Salsify: 通过视频编解码器和传输协议之间更紧密的集成来实现低延迟网络视频
NSDI'18的论文Salsify的中文翻译,以谷歌翻译为主体,并进行了一定的修正
原论文:Salsify: Low-Latency Network Video Through Tighter Integration Between a Video Codec and a Transport Protocol
website: https://snr.stanford.edu/salsify/
original paper: https://www.usenix.org/system/files/conference/nsdi18/nsdi18-fouladi.pdf
slides: https://www.usenix.org/sites/default/files/conference/protected-files/nsdi18_slides_fouladi.pdf
tech video: https://www.youtube.com/watch?v=LPj2ffe7Isk
Abstract
Salsify是一种用于实时Internet视频的新体系结构,该体系结构紧密集成了视频编解码器和网络传输协议,从而使其能够对不断变化的网络状况做出快速响应,并避免引起丢包和排队延迟。为此,Salsify根据对网络容量的当前估计来优化每个帧的压缩长度和传输时间;相反,现有系统通常控制诸如帧速率或比特率之类的长期度量。 Salsify的每帧优化策略依赖于纯功能视频编解码器(purely functional video codec),Salsify使用该编解码器来探索不同质量级别的每个帧的替代编码。
我们开发了一个测试平台,用于以可再现的视频内容和网络条件端到端地评估实时视频系统。 Salsify与五个现有系统(FaceTime, Hangouts, Skype, and WebRTC’s reference implementation with and with-out scalable video coding)相比,可实现更低的视频延迟,并通过可变的网络路径实现更高的视觉质量。
1 Introduction
从1990年代的开创性计划[26,10]到当今广泛使用的视频会议系统,例如FaceTime,Hangouts,Skype和WebRTC,实时视频一直是流行的Internet应用程序。 这些程序应用于人与人之间的视频会议,云游戏,机器人和车辆的远程操作以及任何必须在网络上以低延迟编码和发送视频的设置。
当今的系统通常结合两个组件:传输协议和视频编解码器。 传输组件将压缩的视频发送到接收器,处理确认和拥塞信号,并估计网络路径的平均数据速率。 它将估计值提供给编解码器,编解码器是一个具有自己内部控制循环的独立模块。 编解码器选择编码参数(帧速率和质量设置),并以平均比特率生成近似于估计的网络容量的压缩视频流。
在本文中,我们基于紧密集成到应用程序其余部分中的视频编解码器,探索和评估实时Internet视频的不同设计。这种称为Salsify的系统,将传输协议的逐包拥塞控制与视频编解码器的逐帧速率控制结合到一种算法中。通过使视频传输与网络容量的变化相匹配,Salsify可以避免引起网络内缓冲区溢出或队列延迟。
Salsify的视频编解码器以纯功能性样式实现,这使应用程序能够以不同的质量级别探索每个视频帧的替代编码,以找到压缩长度适合网络瞬时容量的编码。 Salsify避免使用明确的比特率或帧速率;它会在它认为网络可以容纳的时候,发送对应视频帧。
Salsify的各个组件都不是全新的,也不是明确设计为大型系统的一部分。压缩视频格式(VP8 [36])于2008年完成,并已被商业视频会议程序中的更高效格式所取代(例如VP9 [14]和H.265 [32])。 Salsify的VP8编解码器的纯功能实现先前已经描述过[9],其丢失恢复策略与Mosh有关[38,37],并且其速率控制方案基于Sprout [39]。
尽管如此,作为一个具体的系统,Salsify以一种对网络变化做出快速响应而又不会引起数据包丢失或队列延迟的方式集成了这些组件,其性能超过了Skype,FaceTime,Hangouts和部署在Google Chrome浏览器中的WebRTC等最先进的商业水平,无论是否具有可扩展的视频编码-就端到端视频质量和延迟而言(图1给出了结果预览)。
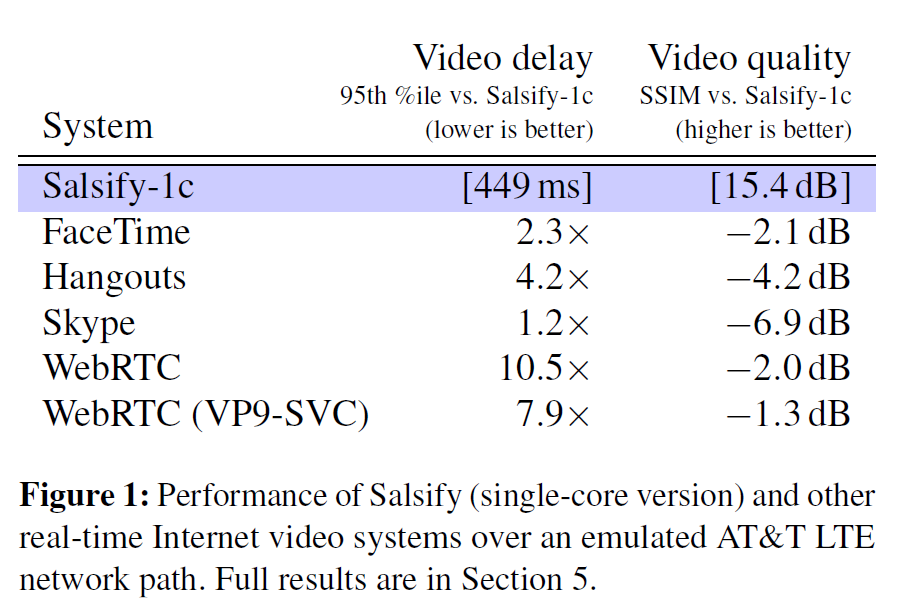
这些结果表明,在这种情况下,对视频编解码器的改进可能已经达到收益递减的地步,但是对视频系统体系结构的更改仍然可以带来显着的收益。如今,是将编解码器和传输协议分开来,它们都有自己独立工作的速率控制算法——当今的应用程序反映了当前的工程实践,其中编解码器在很大程度上被视为黑匣子,但这是以大大降低性能为代价的。 Salsify演示了一种更紧密地集成这些组件的方法,同时保留了它们之间的抽象边界。
本文如下展开。第2节讨论了有关实时视频系统的背景信息和相关工作。我们将在第3节中介绍Salsify的设计和实现,并在第4节中介绍我们用于黑盒视频系统的测量测试平台。第5节介绍了评估结果。我们将在第6节中讨论系统的局限性及其评估。
我们还进行了两项用户研究,以评估质量和延迟对实时视频系统的主观体验质量(QoE)的相对重要性。这些结果在附录A中有更完整的描述。
Salsify是开源软件,本文中报道的实验旨在具有可重复性。评估的源代码和原始数据位于https://snr.stanford.edu/salsify。
github项目网址https://github.com/excamera/alfalfa
2 Related work
自适应视频会议。 Skype和类似的程序通过发送包含压缩视频的用户数据报(UDP),在Internet路径上执行自适应实时视频会议。除Skype之外,此类系统还包括FaceTime,Hangouts和WebRTC系统,这些系统目前正在开发以成为Internet标准[1]。 WebRTC的参考实现[35]已合并到主要的Web浏览器中。
这些系统通常将视频编解码器和传输协议,包括为独立的子系统,各自都有各自的速率控制逻辑和控制回路。传输部分为编解码器提供网络数据速率的估计,视频编码器选择参数(包括帧速率和比特率)以使其平均比特率与网络数据率匹配。相反,Salsify将每个组件的速率控制算法合并为一个,利用视频编解码器的功能特性将每个压缩帧的长度保持在传输对网络容量的瞬时估计之内。
联合源-通道视频编码。 IEEE多媒体社区已经广泛研究了数字分组网络上的低延迟实时视频传输(Zhai&Katsaggelos [45]中提供了一项调查)。这项工作的大部分针对高度复用的网络,在这些网络中,数据速率被视为固定或缓慢变化,并且可以将数据包丢失和排队延迟建模为独立于应用程序自身行为的随机过程(例如[5])。在这种情况下,先前的工作集中于将源编码(视频压缩)与通道编码(前向纠错)相结合,以使应用程序能够适当地承受由独立随机过程引起的丢包和延迟[45]。
Salsify的目标是不同的机制,这在当今的Internet接入网络中更为典型,在该机制中,数据包丢失和排队延迟受应用程序选择发送多少数据的影响[39、13],瓶颈数据速率会迅速衰减,并且面对突发性丢包,前向纠错方案效果不佳[33]。 Salsify的主要贡献不是将视频编码和纠错编码相结合以经受独立发生的丢包,而是在于将视频编解码器和传输协议中的速率控制算法合并起来,以避免引起数据包丢失(例如,由于路由器缓冲区溢出)和因为其自身流量造成的队列延迟。
跨层方案。 诸如SoftCast [19]和Apex [30]之类的方案通过发送结构化的模拟无线信号进入物理层,从而在无线链路上存在更多噪声或干扰时,视频质量会优雅地下降。 IEEE的许多文献[45]也涉及调制模式和功率水平在应用程序控制之下的制度。 Salsify的设计还可以在网络性能下降时正常降级,但是Salsify并非以相同的方式构成跨层方案,它无法到达物理层。 像Skype,FaceTime等一样,Salsify通过Internet发送常规的UDP数据报。
低延迟传输协议。 先前的工作已经为实时应用设计了几种传输协议和容量估计方案[21、18、39、17、6]。 这些方案通常在假定应用程序始终具有可用于传输的数据的情况下进行评估,从而使其能够“全速运行”。 例如,Sprout的评估就是基于这种假设[39]。 在视频编码器以特定帧速率和比特率间歇产生帧的情况下,这种假设被批评为不切实际的[16]。 Salsify的传输协议基于Sprout-EWMA [39],但经过增强使其具有视频感知能力:容量估算方案考虑了视频编解码器生成的间歇性数据(逐帧)。
可伸缩或分层视频编码。多个视频格式支持可伸缩编码,其中编码器可产生多个压缩视频流:一个基础层,然后是一个或多个增强层,改善帧速率,分辨率,或视觉质量。可伸缩编码是H.262(MPEG-2),MPEG-4第2部分,H.264(MPEG-4第10部分AVC)和VP9系统的一部分。实时视频应用程序可以使用可伸缩视频编码来提高可变网络上的性能,因为在拥塞的情况下,应用程序可以立即丢弃增强层,而无需等待视频编解码器适应(但是,质量的提高必须等待编码的增强机会)。可伸缩性在多方视频会议中特别有用,因为它允许中继节点通过丢弃增强层而使发送方的视频流适应不同的接收方网络容量,而无需重新编码。 Salsify是针对单播情况的;在这种情况下,我们评估了现代SVC系统VP9-SVC作为Google Chrome中WebRTC的一部分,发现与常规WebRTC相比,它没有明显改善。
实时视频系统的测量。 先前的工作已经评估了集成视频会议应用程序的性能。 Zhang及其同事[46]改变了模拟网络路径的特征,并衡量了Skype如何改变其网络吞吐量和视频帧速率。 Xu及其同事[41]使用Skype和Hangouts在接收器计算机的显示屏上拍摄秒表应用程序,并在接收器屏幕上并排产生两个时钟,以测量单向视频延迟。
Salsify通过对视频会议系统的视频质量和延迟进行端到端测量来补充这些文献。 从发送计算机的角度来看,测试台似乎是一个USB网络摄像头,可以捕获可重复的视频剪辑。 在接收计算机上,HDMI显示输出被路由回测试台。 该系统测量每帧的端到端视频质量和延迟。
QoE驱动的视频传输。 最近的工作集中在提供自适应视频的优化方法上。 技术包括对类似Netflix的应用程序进行预编码视频块的控制理论选择[44],以及选择中继和路由的推论方法[20、12]。 一般而言,这些系统尝试根据将各种指标映射到单个体验质量(QoE)数字中的功能来评估或最大化性能。 我们的评估包括两项用户研究,以校准QoE指标,并发现视频延迟和视觉质量对实时视频应用(视频聊天和驾驶模拟视频游戏)的体验质量的相对影响。
丢失恢复。 现有系统使用多种技术来从分组丢失中恢复。 RTP和WebRTC应用程序有时会重新传输丢失的数据包,有时会重新编码视频帧的丢失片段[28,25]。 相比之下,Salsify的功能视频解码器将旧状态保留在内存中,直到发送者允许逐出旧状态为止。 如果网络表现出最近的数据包丢失,则编码器可以开始编码新帧的方式仅取决于接收者已确认的较旧状态,即使事实证明丢失了中间数据包,也允许对帧进行解码 。 这种方法被描述为“预防性重传” [37]。
3 Design and Implementation
实时互联网视频系统是通过组合两个组件构建的:传输协议和视频编解码器。在现有系统中,这些组件独立运行,偶尔通过标准化接口进行通信。例如,在WebRTC的开源参考实现中,视频编码器以特定的帧速率从摄像机读取帧并压缩它们,以达到特定的平均比特率。传输协议[17]在大约一秒钟的时间尺度上更新编码器的帧速率和目标比特率。 WebRTC的拥塞响应通常是反应性的:如果视频编解码器产生的压缩帧超出了网络的容量,则传输将发送该压缩帧(即使它将导致数据包丢失或缓冲区过大),但是WebRTC传输随后告诉编解码器:暂停编码新帧,直到清除拥塞为止。 Skype,FaceTime和Hangouts的工作原理类似。
Salsify的架构更紧密地耦合在一起。 Salsify并没有允许视频编解码器以特定的帧速率和目标比特率自由运行,而是将视频编解码器和传输协议的控制回路融合在一起。这种架构使得传输协议在压缩每个帧之前将网络状况与视频编解码器进行通信,从而使Salsify的传输与网络的不断变化的容量相匹配,并在网络可以容纳帧时对其进行编码。
Salsify通过利用其编解码器保存和恢复其内部状态的能力来实现这一目标。 Salsify的传输估计了网络可以安全接受的字节数,而不会丢失或过多地排队。即使在开始为每个帧进行编码之前就知道此数字,对预测会导致视频编码器匹配预定帧长的编码器参数(质量设置)也具有挑战性。
相反,每次需要一帧时,Salsify都会尝试使用两组不同的编码器参数进行编码,以便将可用容量括起来。系统检查生成的压缩帧的编码大小,并选择大小更匹配网络容量估计的进行发送。然后放回由该帧引起的状态,并将其用作下一编码帧的两个版本的基础。我们实现了Salsify的两种版本:一种在一个内核上串行进行两种编码(Salsify-1c),另一种在两个内核上并行进行编码(Salsify-2c)。
3.1 Salsify’s functional video codec
Salsify的视频编解码器使用大约11,000行C ++编写,并使用Google的VP8格式[36]对视频进行编码/解码。它在一个关键方面与VP8和其他编解码器的先前实现有所不同:它以显式的状态传递样式向应用程序公开其编码器/解码器的内部“状态”(我们先前在ExCamera中描述了该编解码器的较早版本[9])。
该状态包括称为参考图像的先前已解码帧的副本,以及用于熵编码的概率表。在1280×720的分辨率下,VP8解码器的内部状态约为4 MiB。为了压缩新图像,视频编码器利用其与状态中的参考图像的相似性。视频解码器可以被建模为自动机,并使用编码帧作为输入,以引起源状态和目标状态之间的状态转换。自动机从源状态开始,消耗压缩帧,输出图像进行显示,然后过渡到目标状态。
在典型的实现中,无论是硬件还是软件,此状态都由编码器/解码器在内部维护,并且应用程序无法访问。编码器将原始图像流作为输入,并产生压缩的位流。对帧进行编码时,编码器的内部状态会更改,无法撤消操作并返回到先前状态。相比之下,Salsify的VP8编码器和解码器是纯函数,没有副作用,所有状态都在外部维护。该接口是:
$$decode(state, frame) → (state^{'}, image)$$
$$encode(state, image, quality) → frame$$
使用此接口,应用程序可以探索用于编码每个帧的不同质量选项,并从所需状态开始解码。 这使Salsify可以(1)以与网络容量匹配的大小和质量编码帧,并且(2)有效地从数据包丢失中恢复。
进行编码以匹配网络容量。当前的视频编码器(包括Salsify的视频编码器)无法压缩单个帧以准确匹配指定的编码长度。只有在压缩帧之后,编码器才能以任何精度发现结果长度。结果,当前的视频会议系统通常会通过将编码器随时间变化的平均比特率与网络的数据率进行匹配来平均地跟踪网络的容量。
相比之下,Salsify利用其视频编码器的功能特性,根据对网络容量的当前估计,优化每个帧的压缩长度。通过运行两个编码器(串行或并行)为每个帧分配两个压缩级别,这些编码器使用相同的内部状态但使用不同的质量设置进行初始化。 Salsify选择最适合网络条件的结果帧,在知道压缩帧的确切大小之后,将要发送哪个版本的决定延迟到尽可能晚。由于编码器以显式的状态传递方式实现,因此可以将其重新同步到由选择发送的任何版本的帧引起的状态。 Salsify会根据周围环境(较高,较低一种)为下一帧选择两个质量设置,以在前一帧中成功的设置为准。
还有第三种选择:如果两个版本都超过估计的网络容量,则不发送任何一个版本。在这种情况下,下一帧将基于相同的内部状态进行编码。因此,Salsify能够通过以其他视频应用程序无法跳过的方式跳过帧(传统应用程序只能在输入到编码器的输入时暂停帧——它们不能在编码后未引起破坏之前跳过帧),从而改变帧的节奏以适应网络。
丢失恢复。 Salsify的损失恢复策略可以概括为选择正确的源状态以对帧进行编码。在没有丢失的情况下,编码器会生成一系列已压缩的帧,每个帧都取决于前一帧产生的目标状态,即使尚未确认已接收到该帧,发送方也会假设所有在传输的数据包都将抵达。但是,数据包丢失会导致接收器的帧不完整或丢失,从而使解码器处于与发送器所假定的状态不同的状态,并破坏了视频解码流。为了解决这个问题,当发送方检测到数据包丢失时(通过来自接收方的ACK,第3.2节),它通过创建依赖于接收方明确确认的状态的帧来重新同步接收方的状态(算法1.3和算法2.3);即使中间数据包丢失,这些帧也可以被接收器使用。这种方法要求发送者和接收者将目标状态序列保存在内存中,只有在安全时才将其删除。具体来说,在接收到基于某种状态的帧时,接收器将丢弃所有较旧的帧。当发送方收到某个状态的ACK时,它将丢弃所有较旧的状态。
在数据包重新排序的情况下,如果在当前帧完成之前接收到新帧的片段,则接收方仍会解码不完整的帧(这会将其解码器置于无效状态)并继续处理下一个帧。发送方将这种情况识别为数据包丢失,并以相同的方式进行处理。帧片段内的数据包重新排序不会造成破坏,因为接收方首先会等待所有片段,然后再对帧进行重组和解码。
3.2 Salsify’s transport protocol
我们用大约2,000行C ++实现了Salsify的传输协议。发送方通过UDP将压缩的视频帧发送到接收方,接收方进行确认答复。每个视频帧分为一个或多个MTU大小的片段。
除了帧序列号和片段索引,每个帧的标头都包含其源状态的哈希值和目标状态的哈希值。有了这些标题,压缩的视频帧就成为幂等的运算符,它在接收器上作用于所标识的源状态,将其转换为所标识的目标状态,并生成要在该过程中显示的图片。在发送方要使用目标状态进行丢失恢复的情况下,接收方将目标状态存储在内存中。作为对每个片段的答复,接收器发送包含帧号和片段索引以及其当前解码器哈希值的确认消息。
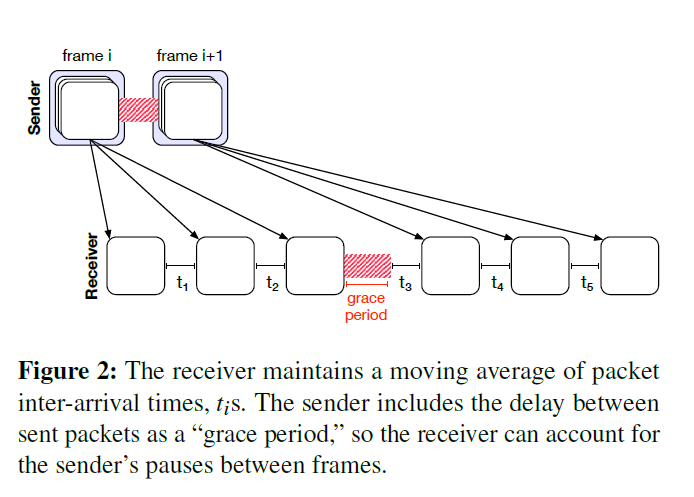
接收器将进入的数据包视为数据包序列[21、18]来探测网络,并保持数据包到达时间的移动平均值,类似于WebRTC [17、6]和Sprout-EWMA [39]。该估计值以确认包的形式传达给发送方。但是,发送方不会连续发送-在帧之间暂停。结果,一帧的最后一个片段与下一帧的第一个片段之间的到达时间对网络容量的指示没有帮助(图2)。这种暂停可能会使接收者对网络进行人为的悲观估计,因为应用程序没有传输“全油门”。为了解决这个问题,发送方在每个片段中都包含一个宽限期,该宽限期告诉接收方当前和先前片段发送之间的持续时间。当接收到片段$i$时,接收器将平滑的到达时间$τ_i$计算为
$$\tau_i\leftarrow\alpha(T_i-T_{i-1}-{grace-period})+(1-\alpha)\tau_{i-1}$$
其中$T_i$是接收到的时间片段$i$。在我们的实现中,α的值为0.1,近似于最后十次到达的移动平均值。
在发送方,Salsify的传输协议根据接收方报告的最新平均到达间隔时间,估算出所需的帧大小。为了在时间步$i$计算目标大小,发送方首先通过上次发送的数据包的索引和最后确认的数据包的索引相减,估算在传递过程中的数据包数量的上限$N_i$。令$τ_i$为接收机在$i$处报告的最新平均到达间隔时间。如果发送方旨在保持端到端延迟小于$d$(在我们的实现中设置为100 ms)以保持交互性,则在传输中的数据包不得超过$d /τ_i$个数据包。因此,目标大小是$(d /τ_i-N_i)MTU$大小的片段(算法1.6)。发送时,发送方将选择不超过此长度的最大帧。如果两个编码版本都超过此大小,则发送方将丢弃该帧,然后继续发送下一个帧。为了能够接收来自接收者的新反馈,如果连续跳过四个以上的帧,则发送者发送低质量版本(算法2)。


4 Measurement testbed
为了评估Salsify,我们为实时视频系统构建了一个端到端的测试平台,该平台将发送方和接收方视为黑匣子,模拟时变网络,同时测量影响体验质量的应用级视频指标。 本节描述了测试平台的指标和要求(第4.1节),其设计(第4.2节)及其实现(第4.3节)。
4.1 Requirements and metrics
要求。测试平台需要将自己呈现为网络摄像头,并以可重复的方式向未经修改的实时视频系统提供60 fps的高清视频剪辑。同时,测试平台需要模拟系统中发送方和接收方之间的变化网络链接,并将仿真网络的时变行为同步到测试视频。最后,测试台需要捕获未经修改的接收器显示出来的帧,并量化其质量(相对于源视频)和延迟。
指标。测量测试平台使用两个主要指标来评估实时视频系统的视频质量和视频延迟。为了质量,我们使用平均结构相似度(SSIM)[34],这是一种将接收到的帧与源视频进行比较的标准度量。
为了测量交互式视频延迟,测试台计算了它提供帧的时间(充当网络摄像头)与接收器显示同一帧的时间(减去测试台的固有延迟,我们在第5.1节中测量)之间的差。
对于60 fps网络摄像头输入中未发送或接收机未显示的帧,我们将其到达时间分配为等于所显示的下一帧。结果,延迟度量奖励以较高帧速率发送的系统。该度量标准的目的是考虑系统选择的帧速率以及它选择传输的帧的延迟。每小时传输一帧,但这些帧始终立即到达的系统,即使确实传输的罕见帧很快到达,也将被测量为具有长达一个小时的延迟。以每秒60帧的速度传输但在一小时的磁带延迟下传输的系统也将被表示为具有较大的延迟。
4.2 Design
图3概述了测试平台的硬件布置。在较高的层次上,测试平台的工作原理是将视频注入到发送客户端中,模拟发送方和接收方之间的网络状况,并在接收客户端捕获显示的视频。然后,它将注入到发送方的帧与从接收方捕获的帧进行匹配,并计算延迟和质量。
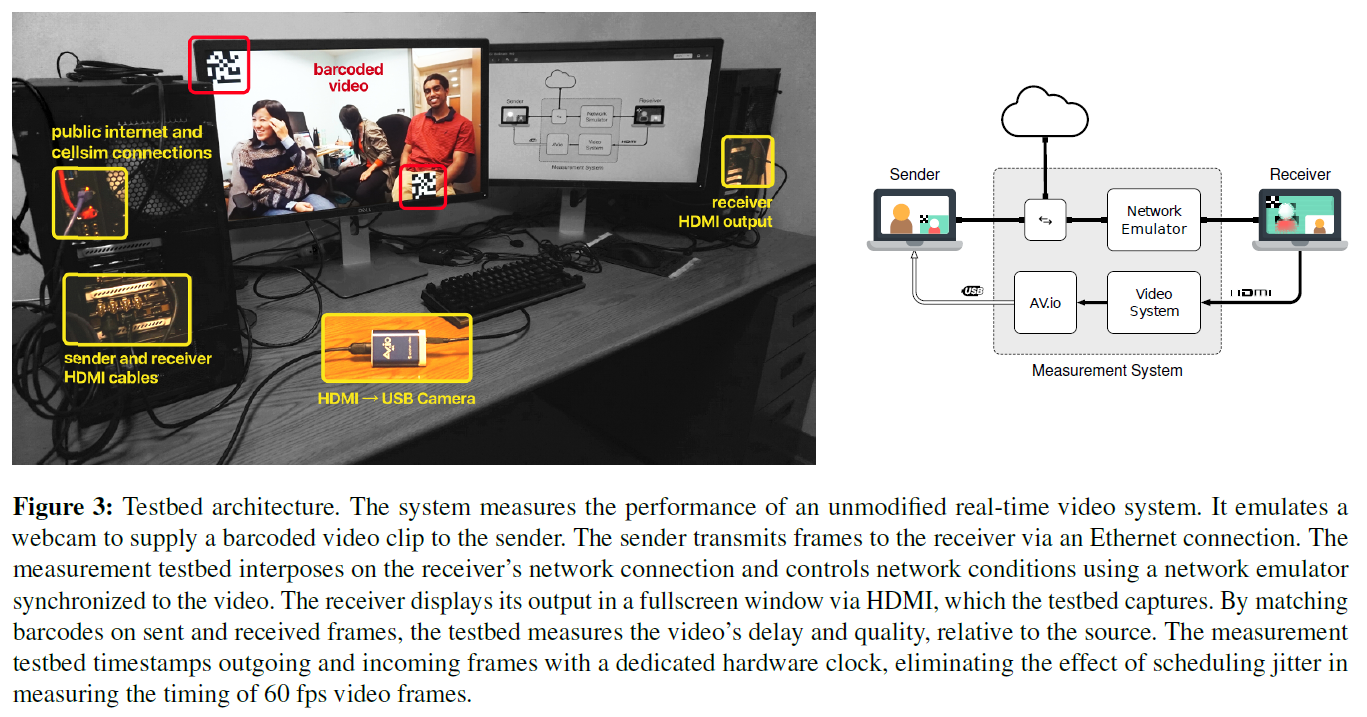
硬件。发送器和接收器是两个计算机,它们运行测试中的实时视频应用程序的未更改版本。每个端点到测试床的视频接口是一个标准接口:对于发送方,测试床模拟UVC网络摄像头设备。对于接收器,测试台捕获HDMI视频输出。
测量测试台还控制发送方和接收方之间的网络连接。每个端点都有一个到测试平台的以太网连接,该以太网桥将端点相互连接并互连到Internet。
视频分析。为了计算与视频相关的指标,测试平台记录发送机每帧预先显示的时间,捕获接收器的显示输出,并在同一时钟下将每个到达的帧在硬件中记录时间。
测试平台将从接收器捕获的每个帧与在发送者处注入的帧进行匹配。为此,测试台会对视频进行预处理,以在每个帧的左上角和右下角添加两个小的条形码。1这些条形码一起占用了帧面积的3.6%。每个条形码编码一个在视频过程中唯一的64位随机数。图3和4中显示了一个示例帧。在后处理中,通过匹配已发送和已接收帧上的条形码,然后比较相应的帧,可以计算质量和延迟指标。

4.3 Implementation
测量测试台是具有专用硬件的PC工作站。为了捕获和播放原始视频,系统使用Blackmagic Design DeckLink 4K Extreme 12G卡,该卡可以发射和捕获HDMI视频。 DeckLink使用其自己的硬件时钟对传入和传出的帧进行时间戳记。要将传出的视频转换为UVC网络摄像头界面,测试台使用Epiphan AV.io HDMI到UVC转换器。以1280×720和每秒60帧的分辨率,原始视频每秒消耗1.8吉比特。测试平台使用两个SSD来同时播放和捕获原始视频。
测量测试平台使用Xiph Daala工具包计算SSIM。对于网络仿真,我们使用Cellsim [39],始终启动与实验开始同步的程序。为了探索对网络中排队行为的敏感性,我们为Cellsim配置了一个DropTail队列,该队列的丢弃阈值为64、256或1024个数据包。最终,我们发现应用程序对此参数不敏感,并使用256个数据包的缓冲区进行了其余测试。蜂窝轨迹(trace)的往返延迟设置为40 ms。我们开发了用于条形码,播放,捕获和分析视频的新软件。它包含约2500行C ++。
5 Evaluation of Salsify
该评估回答了以下问题:在各种现实世界和合成网络轨迹上运行时,Salsify与五个流行的实时视频系统在视频延迟和视频质量方面相比如何? 总而言之,我们发现,在所测试的系统中,Salsify在一系列蜂窝轨迹(trace)上可观的余量提供了最佳的延迟和质量。 Salsify还在合成间歇性链接和仿真Wi-Fi链接上表现出色。
5.1 Setup, calibration, and method
建立。我们使用第4节中描述的测量测试平台进行了所有实验。图5列出了应用程序和版本。在macOS上进行的测试使用了运行macOS Sierra的较新型号MacBook Pro笔记本电脑。 WebRTC(VP9-SVC)在Chrome上使用命令行参数运行,以启用VP9可伸缩视频编码;这些命令行参数是由Google Chrome小组的视频压缩工程师提出的[2](The arguments were: out/Release/chrome --enable-webrtc-vp9-svc-2sl-3tl --fake-variations-channel=canary --variations-server-url=https://clients4.google.com/chrome-variations/seed)。Linux上的测试在装有最新Intel Xeon E3-1240v5处理器和32 GiB RAM的台式计算机上使用Ubuntu 16.10。我们使用同一台Linux计算机测试了Salsify。

在实验过程中,所有机器都物理上位于同一房间内,并通过千兆以太网连接相互连接并与公共Internet连接。在进行实验时,确保在任何客户端计算机上都没有其他计算或网络密集型进程在运行。
校准。为了校准测量测试台,我们在没有网络的情况下进行了环回实验:我们将测试台的UVC输出连接到上述台式计算机,配置该计算机使用ffplay在其自己的HDMI输出上全屏显示传入的帧,然后将输出连接返回到测试台。
我们发现通过环回连接的延迟为4帧,约67毫秒;在所有其他实验中,我们从原始结果中减去了这种固有延迟。输出和输入图像之间的差异可以忽略不计,SSIM超过25 dB,相当于99.7%的绝对相似度。
方法。对于下面的每个实验,我们在测试平台上使用指定的网络轨迹(trace)评估每个系统,并按照4.1节中的描述计算指标。激励是三个人进行一次典型的视频会议通话的十分钟,60 fps,1280×720的视频。我们按照第4.2节中的描述对该视频进行了预处理——在每个帧上标记了条形码。网络轨迹(trace)足够长,可以覆盖视频的整个长度。
5.2 Results
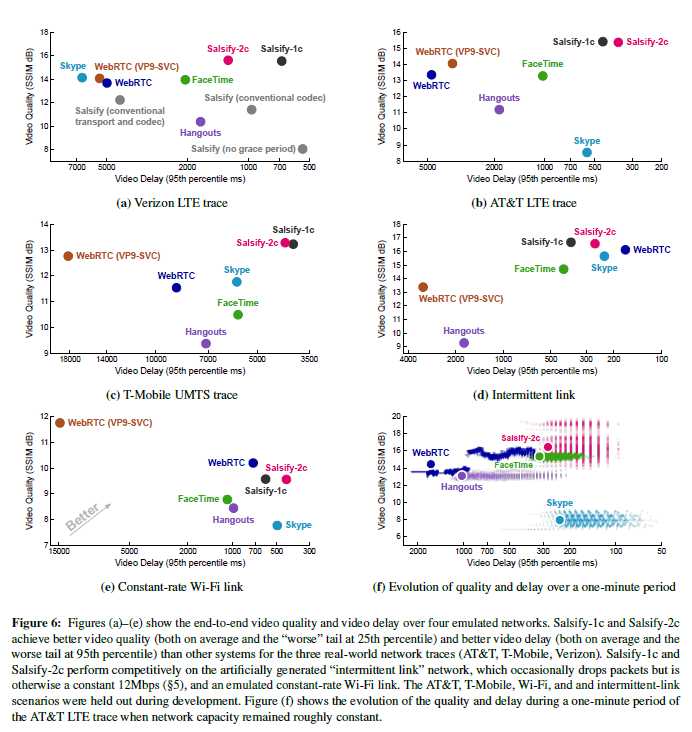
实验1:可变的蜂窝路径。在本实验中,我们使用Mahimahi网络仿真工具[27]来测量Salsify和其他系统,它们使用AT&T LTE,T-Mobile UMTS(“ 3G”)和Ver-izon LTE蜂窝网络轨迹。实验时间为10分钟。蜂窝轨迹在整个网络容量范围内随时间变化:从大于20 Mbps到小于100 kbps。尽管在开发当前的1核和2核版本之前,先前在这些迹线上评估了较早的(8核)Sal-sify版本,但目前移除了AT&T LTE和T-Mobile的轨迹,并未在Salsify的开发中使用。 。
图6a,6b和6c显示了每条迹线上每种方案的结果。 Salsify的单核版本(Salsify-1c)和双核版本(Salsify-2c)在质量和延迟(以及用户研究中的任一QoE模型)方面均优于所有竞争方案。我们发现Salsify的串行和并行版本之间的性能差异不大。这表明在测试的PC工作站上,两个视频编码器并行运行并不是很重要。
Salsify的丢失恢复策略要求发送者和接收者在内存中保留一组解码器状态,以便在发生丢失时从已知状态中恢复。接收者确认状态后,或发送者根据状态发送帧后,其他程序将丢弃较早的状态。在我们的AT&T LTE跟踪实验中,Salsify-2c发送方在执行过程中平均保留6个状态,每个状态大小为4 MiB,而接收方平均一次保留3个状态。此外,在同一实验中,Salsify-2c在50%的情况下选择了质量较好的选项,在32%的情况下选择了低质量的选项,而在发送帧的机会中有18%根本没有发送帧。
图6f显示了在网络路径大部分处于稳定状态的AT&T LTE跟踪的一分钟时间内,不同方案的质量和延迟如何变化。
实验2:间歇性链接。在此实验中,我们评估了Salsify的损失恢复能力方法。我们在两态的间歇链路上运行每个系统。链路的容量为12 Mbps,直到出现“故障”为止,它不会掉线,这种情况平均发生在五秒钟后(呈指数分布)。在故障期间,平均丢弃0.2秒后,所有数据包都将被丢弃,直到出现“恢复”事件为止。实验时间为10分钟。
图6d显示了每种方案的结果。 Sal-sify方案的质量最高,其延迟比除Skype和WebRTC之外的所有方案都更好。 Sal-sify和WebRTC都在这种情况下处于帕累托前沿。需要进一步调整以查看Salsify是否可以在不影响质量的情况下改善其延迟。
实验3:模拟Wi-Fi。在这个实验中,我们评估了Salsify和其他系统在一条充满挑战的网络路径上的情况,该路径与蜂窝跟踪不同,它不会随时间改变容量。该仿真Wi-Fi网络路径与长距离自由空间Wi-Fi跳的行为相匹配,仿真参数取自[42],包括约570 kbps的平均数据速率和Pois-son数据包到达。图6e显示了结果。 Salsify位于Pareto边界,并且当网络数据速率不随时间变化时,WebRTC也会表现出色。
实验4:成分分析研究。在本实验中,我们逐一删除了Salsify中实现的新组件,以更好地了解它们对系统总体性能的贡献。首先,我们删除了Salsify的传输协议的功能,这使其具有视频感知功能——“宽限期”用于考虑视频编解码器的间歇传输。这种配置的性能下降在图6a中显示为“ Salsify(无宽限期)点”;如果没有此组件,Salsify会低估网络容量并发送低质量,低比特率的视频。
然后,我们删除了Salsify的显式状态传递样式视频编解码器,将其替换为状态对应用程序不透明的常规编解码器,并且必须预先预测适当的编码参数(而不是事后为每个帧选择最佳压缩版本)。编解码器通过对原始帧的抽取版本执行质量设置的二分搜索,尝试达到目标帧大小并将结果大小外推到完整帧来预测这些参数。使用正常Salsify中的相同传输协议选择目标大小。结果在图6a中也显示为“ Salsify(常规编解码器)”。
如图所示,Salsify的性能再次大幅下降。这是两个因素的结果:(1)传输在传输时不再有权选择帧;如果在压缩视频帧的过程中容量估算值发生变化,Salsify可能会导致延迟或错过提高视频质量的机会,并且(2)任何编解码器都难以选择合适的质量设置提前达到目标规模;编码器可能会低于或超过其目标。
最后,我们创建了一个端到端系统,通过删除Sal-sify的视频编解码器和传输协议的独特功能来模拟常规视频会议系统的行为。此实现中的传输协议不是逐帧操作,而是估计网络的平均数据速率,并每秒更新一次视频编解码器的质量设置。如图6a中的“ Salsify(常规传输和编解码器)点”所示,此实现具有与Skype和WebRTC相似的性能。
我们得出的结论是,Salsify的每项独特功能(视频感知传输协议,纯功能编解码器以及它们之间的逐帧耦合(合并每个模块的速率控制算法))都对系统的整体性能做出了积极贡献。
实验5:容量增加。在此实验中,我们评估了Salsify,Skype和WebRTC如何处理网络,数据速率逐渐降低(到零),然后网络容量逐渐恢复。我们创建了图7a和7b中以浅灰色描绘的合成网络轨迹。实验时间为20秒。
图7a显示了每种方案尝试通过链路发送的数据传输速率与时间的关系。 Salsify的吞吐量随着链接容量的增加而平稳下降,然后恢复正常。结果是Salsify的视频显示在链路容量恢复后迅速恢复,如图7b所示。
相比之下,Skype对网络容量下降的反应很慢,结果导致链路和待机队列丢失,这两者都会将生成的视频延迟几秒钟。 WebRTC对链路容量的损失做出反应,但是在网络恢复后最终陷入了一种不良模式。链接开始恢复后的八秒钟内,接收器仅显示少量帧(标有蓝点)。
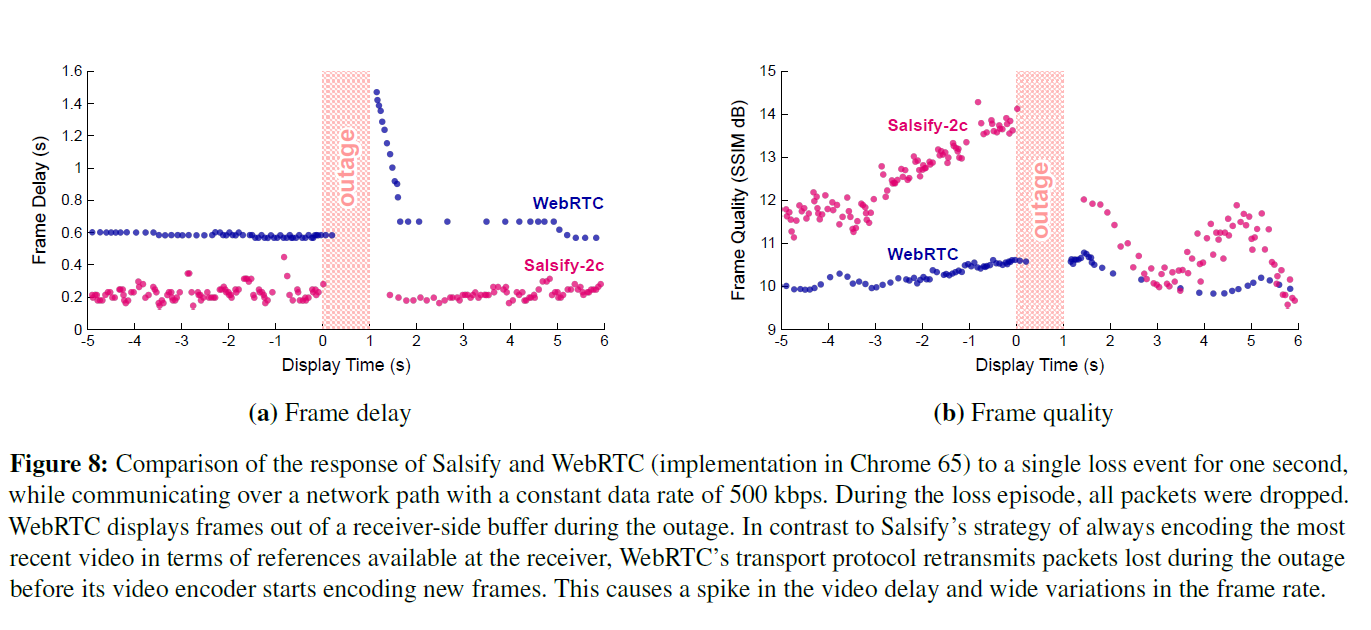
实验6:一秒钟的丢包实验。在本实验中,我们通过引入单个丢包1 s来比较数据包丢失对Salsify-2c和WebRTC的影响,同时在仿真链路上以500 kbps的恒定数据速率运行每个应用程序。计划在中断期间交付的所有数据包均被丢弃。图8显示了结果。网络恢复后,WebRTC的传输协议会重新传输中断期间丢失的数据包,从而在其视频编解码器开始编码新的视频帧之前引起延迟峰值(WebRTC的基准延迟也大得多)。 Salsify的视频编解码器和传输协议之间没有独立性;网络恢复后,Salsify的功能视频编解码器可以立即根据接收器上已经存在的参考图像对新帧进行编码。这样可以更快地从中断中恢复。
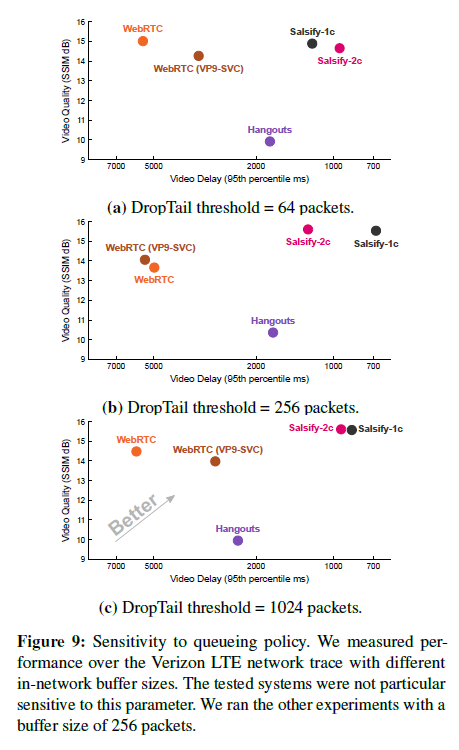
实验7:对队列策略的敏感性。在此实验中,我们量化了网络缓冲区大小对Verizon-LTE网络轨迹下的Salsify,Hangouts,WebRTC和Web-RTC(VP9-SVC)的性能影响。图9中的图显示了在各种DropTail阈值(64、256和1024 MTU大小的数据包)上,每个系统在迹线上的性能。缓冲区大小的选择对受测系统的性能没有显着影响,这可能是因为所有方案都在努力降低延迟,因此不太可能建立足够大的站立队列来查看DropTail导致的数据包丢弃。我们使用中间设置(256个数据包)运行其余测试。
5.3 Modifications to systems under test
尽管只要发送方通过USB网络摄像头接受输入并且接收方通过HDMI全屏显示输出,测试台就可以与未经修改的实时视频系统配合使用,但实际上,我们发现如果要对商用系统进行合理的评估,那么一些细微的修改是需要的。我们在这里描述这些。
FaceTime双向视频和自我查看。与我们测试的其他视频会议程序不同,无法将FaceTime配置为禁用双向视频传输。在评估FaceTime时,我们实际涵盖了接收器的网络摄像头,以最大程度地减少接收器需要发送的数据量。
而且,像大多数视频会议程序一样,Face-Time提供一个自查看窗口,因此用户可以看到他们正在发送的视频。无法在Face-Time中禁用此功能,它存在于我们的测量测试台捕获的帧中。为了防止这种情况不公平地降低FaceTime的SSIM得分,我们在计算SSIM之前在后处理(已发送和已接收的原始视频)中涂黑了自视窗口。这些区域约占框架总面积的4%。
Hangouts和WebRTC水印和自我查看。默认情况下,Google Hangouts和我们的参考Web-RTC客户端(appr.tc)具有多个水印和自查看窗口。由于这些程序在浏览器中运行,因此我们修改了它们的CSS文件以删除这些工件,从而可以准确地测量SSIM。
Hangouts未建立P2P连接。与我们评估过的所有其他系统不同,Google Hangouts没有在两台客户端计算机之间建立直接UDP连接。而是,客户端仍通过UDP通过Google中继服务器进行通信。我们通过对客户端计算机使用的Google服务器执行ping操作来测量此延迟。在所有情况下,往返延迟均<20 ms,平均约为5 ms。
6 Limitations and Future Work
Salsify及其评估具有许多重要的局限性和未来工作的机会。
6.1 Limitations of Salsify
没有音频。 Salsify不编码或传输音频。在测试其他应用程序时,我们禁用了音频,以避免给Salsify带来不公平的优势。向视频会议系统添加音频会为未来QoE优化中的工作创造许多机会-例如,通常有利于接收器延迟缓冲区中的音频以在面对网络抖动的情况下进行不间断的播放,甚至为此付出延迟增加的代价。同样应在多大程度上延迟视频以使其与音频保持同步,以及在这些方面评估任何折中的正确指标是什么?
大多数编解码器不支持状态的保存/恢复。 Sal-sify包含VP8编解码器(一种我们尚未修改的现有格式),另外,该编解码器采用功能样式,并允许应用程序保存和恢复其内部状态。常规编解码器(无论是硬件还是软件)都不支持该接口,尽管我们希望这些结果将鼓励实现者公开这种接口。在功耗受限的设备上,只有硬件编解码器才具有足够的电源效率,因此我们希望Salsify的结果能够像Salsify一样激励硬件编解码器实现者公开状态。
改进的常规编解码器可能使Salsify的功能编解码器变得不必要。 Salsify的纯功能编解码器的优势主要在于它能够(通过反复试验和错误)生成压缩帧,这些帧的长度与传输协议对网络瞬时容量的估计相匹配。在某种程度上,常规编解码器也增加了此功能,在这种情况下,功能性编解码器的优势将缩小。
当网络路径变化最大时,收益最大。 Salsify的主要贡献在于将速率控制算法与传输协议和视频编解码器相结合,并利用功能编解码器来生成与网络瞬时容量相匹配的单个压缩帧,即使网络瞬时容量是高度可变的。在表现出这种可变性的网络路径上(例如,移动时的蜂窝网络),Salsify展示出了优于当前应用程序的显着性能优势。在变化不大的网络上,Salsify的性能更接近于现有应用程序。
6.2 Limitations of the evaluation
单向视频。我们的实验使用了专用的发送器和接收器,而典型的视频通话具有双向视频。这是因为测试台只有一个Blackmagic卡(和一对高速SSD),并且不能同时发送和捕获两个视频流。
跟踪不反映共享同一队列的多个流。为了公平地评估每个应用程序,我们使用了相同的测试视频,并运行了一系列可复制的网络仿真器。我们没有在“狂野”的现实世界中评估这些方案。基于跟踪的网络仿真会重播从蜂窝网络捕获的实际数据包时序(正向和反向)。这些跟踪记录了多种现象,包括多跳的影响,反向路径中的ACK压缩以及记录跟踪时来自其他流和共享网络的用户的交叉流量,从而降低了网络路径的可用数据速率。但是,该仿真不会捕获与被测应用程序共享相同瓶颈队列的交叉通信。一般来说,当瓶颈队列与“缓冲膨胀”交叉流量共享时,没有任何端到端应用程序可以实现低延迟视频[13]。
7 Conclusion
在本文中,我们介绍了Salsify,这是一种用于实时Internet视频的新体系结构,该体系结构紧密集成了视频编解码器和网络传输协议。 Salsify通过以下三种主要方式对现有系统进行了改进:(1)视频感知传输协议无需“全油门”源就可以准确估计网络容量,(2)功能视频编解码器允许应用进行多种设置的实验(3)Salsify将速率控制算法合并到视频编解码器和传输协议中,以避免因自身流量而引起丢包和排队延迟。
在端到端评估中,与5种现有系统(包括Skype,FaceTime,Hang-outs和WebRTC的参考实现,无论有无可缩放视频编码)相比,Salsify均实现了更低的端到端视频延迟和更高的质量( VP9-SVC)。
值得注意的是,Salsify实现了比其他系统更高的视觉质量,因为Salsify使用了我们自己的VP8编解码器实现-一种很大程度上被取代的压缩方案,以及该方案的朴素的编码器。结果表明,在这种情况下,对视频编解码器的进一步改进可能已达到收益递减的地步,但是对视频系统体系结构的更改仍然可以带来巨大的收益。
Acknowledgments
We thank the NSDI reviewers and our shepherd, Kyle Jamieson, for their helpful comments and suggestions. We are grateful to James Bankoski, Josh Bailey, Danner Stodolsky, Timothy Terriberry, and Thomas Daede for feedback throughout this project, and to the participants in the user study. This work was supported by NSF grant CNS-1528197, DARPA grant HR0011-15-2-0047, the NSF Graduate Research Fellowship Program (JE), and by Google, Huawei, VMware, Dropbox, Facebook, and the Stanford Platform Lab.
References
[1] ALVESTRAND, H. T. Overview: Real Time Protocols for Browser-based Applications. Internet-Draft draft-ietf-rtcweb-overview-16, Internet Engineering Task Force, Nov. 2016. Work in Progress. [2] CHEN, M., PONEC, M., SENGUPTA, S., LI, J., AND CHOU, P. A. Utility maximization in peer-to-peer systems. In ACM SIGMETRICS (June 2008). [3] CHEN, X., CHEN, M., LI, B., ZHAO, Y., WU, Y., AND LI, J. Celerity: A low-delay multi-party conferencing solu-tion. IEEE Journal on Selected Areas in Communications 31, 9 (Sept. 2013), 155–164. [4] CHENG, R., WU, W., CHEN, Y., AND LOU, Y. A cloud-based transcoding framework for real-time mobile video conferencing system. In IEEE MobileCloud (Apr. 2014). [5] CHOU, P. A., AND MIAO, Z. Rate-distortion optimized streaming of packetized media. IEEE Transactions on Multimedia 8, 2 (April 2006), 390–404. [6] CICCO, L. D., CARLUCCI, G., AND MASCOLO, S. Ex-perimental investigation of the Google congestion control for real-time flows. In ACM FhMN (Aug. 2013). [7] ELMOKASHFI, A., MYAKOTNYKH, E., EVANG, J. M., KVALBEIN, A., AND CICIC, T. Geography matters: Build-ing an efficient transport network for a better video confer-encing experience. In CoNEXT (Dec. 2013). [8] FENG, Y., LI, B., AND LI, B. Airlift: Video conferencing as a cloud service. In IEEE ICNP (Feb. 2012). [9] FOULADI, S., WAHBY, R. S., SHACKLETT, B., BAL-ASUBRAMANIAM, K. V., ZENG, W., BHALERAO, R., SIVARAMAN, A., PORTER, G., AND WINSTEIN, K. En-coding, fast and slow: Low-latency video processing using thousands of tiny threads. In 14th USENIX Symposium on Networked Systems Design and Implementation (NSDI’17)(2017), USENIX Association, pp. 363–376. [10] FREDERICK, R. Experiences with real-time software video compression. In Proceedings of the Sixth Inter-national Workshop on Packet Video (1994). [11] FUND, F., WANG, C., LIU, Y., KORAKIS, T., ZINK, M., AND PANWAR, S. S. Performance of DASH and WebRTC video services for mobile users. In IEEE PV (Dec. 2013). [12] GANJAM, A., JIANG, J., LIU, X., SEKAR, V., SIDDIQUI, F., STOICA, I., ZHAN, J., AND ZHANG, H. C3: Internet-scale control plane for video quality optimization. In NSDI (May 2015). [13] GETTYS, J., AND NICHOLS, K. Bufferbloat: Dark buffers in the Internet. Queue 9, 11 (Nov. 2011), 40:40–40:54. [14] GRANGE, A., DE RIVAZ, P., AND HUNT, J. VP9 Bit-stream & Decoding Process Specification version 0.6, March 2016. http://www.webmproject.org/vp9/. [15] HAJIESMAILI, M. H., MAK, L., WANG, Z., WU, C., CHEN, M., AND KHONSARI, A. Cost-effective low-delay cloud video conferencing. In IEEE ICDCS (June 2015). [16] HERMANNS, N., AND SARKER, Z. Congestion control issues in real-time communication—“Sprout” an example. Internet Congestion Control Research Group. https://datatracker.ietf.org/meeting/88/materials/slides-88-iccrg-3. [17] HOLMER, S., LUNDIN, H., CARLUCCI, G., CICCO, L. D., AND MASCOLO, S. A Google congestion con-trol algorithm for real-time communication, 2015. draft-alvestrand-rmcat-congestion-03. [18] JAIN, M., AND DOVROLIS, C. End-to-end available band-width: Measurement methodology, dynamics, and rela-tion with TCP throughput. In Proceedings of the 2002 Conference on Applications, Technologies, Architectures, and Protocols for Computer Communications (2002), SIG-COMM ’02, ACM, pp. 295–308. [19] JAKUBCZAK, S., AND KATABI, D. A cross-layer design for scalable mobile video. In MobiComm (Sept. 2011). [20] JIANG, J., DAS, R., ANANTHANARAYANAN, G., CHOU, P. A., PADMANABHAN, V. N., SEKAR, V., DOMINIQUE, E., GOLISZEWSKI, M., KUKOLECA, D., VAFIN, R., AND ZHANG, H. VIA: Improving internet telephony call qual-ity using predictive relay selection. In SIGCOMM (Aug. 2016). [21] KESHAV, S. A control-theoretic approach to flow control. In Proceedings of the Conference on Communications Architecture & Protocols (1991), SIGCOMM ’91, ACM, pp. 3–15. [22] LI, J., CHOU, P. A., AND ZHANG, C. Mutualcast: An ef-ficient mechanism for content distribution in a peer-to-peer (P2P) network. Tech. Rep. MSR-TR-2004-98, Microsoft Research, 2004. [23] LIANG, C., ZHAO, M., AND LIU, Y. Optimal bandwidth sharing in multiswarm multiparty P2P video-conferencing systems. IEEE/ACM Trans. Networking 19, 6 (Dec. 2011), 1704–1716. [24] LIU, X., DOBRIAN, F., MILNER, H., JIANG, J., SEKAR, V., STOICA, I., AND ZHANG, H. A case for a coordinated Internet video control plane. In SIGCOMM (Aug. 2012). [25] LUMIAHO, L., AND NAGY, M., Oct. 2015. Er-ror Resilience Mechanisms for WebRTC Video Communications http://www.callstats.io/2015/10/30/error-resilience-mechanisms-webrtc-video/. [26] MCCANNE, S., AND JACOBSON, V. Vic: A flexible frame-work for packet video. In Proceedings of the Third ACM International Conference on Multimedia (1995), MULTI-MEDIA ’95, ACM, pp. 511–522. [27] NETRAVALI, R., SIVARAMAN, A., DAS, S., GOYAL, A., WINSTEIN, K., MICKENS, J., AND BALAKRISHNAN, H. Mahimahi: Accurate record-and-replay for HTTP. In USENIX Annual Technical Conference (2015), pp. 417–429. [28] OTT, J., AND WENGER, D. S. Extended RTP Profile for Real-time Transport Control Protocol (RTCP)-Based Feedback (RTP/AVPF). RFC 4585, July 2006. [29] PONEC, M., SENGUPTA, S., CHIN, M., LI, J., AND CHOU, P. A. Multi-rate peer-to-peer video conferencing: A distributed approach using scalable coding. In IEEE ICME (June 2009). [30] SEN, S., GILANI, S., SRINATH, S., SCHMITT, S., AND BANERJEE, S. Design and implementation of an “ap-proximate” communication system for wireless media ap-plications. In Proceedings of the ACM SIGCOMM 2010 Conference (2010), SIGCOMM ’10, ACM, pp. 15–26. [31] SEUNG, Y., LENG, Q., DONG, W., QIU, L., AND ZHANG, Y. Randomized routing in multi-party internet video conferencing. In IEEE IPCCC (Dec. 2014). [32] SULLIVAN, G. J., OHM, J.-R., HAN, W.-J., AND WIE-GAND, T. Overview of the high efficiency video coding (HEVC) standard. IEEE Trans. Cir. and Sys. for Video Technol. 22, 12 (Dec. 2012), 1649–1668. [33] SWETT, I. QUIC FEC v1. https://docs.google.com/document/d/ 1Hg1SaLEl6T4rEU9j-isovCo8VEjjnuCPTcLNJewj7Nk. [34] WANG, Z., BOVIK, A. C., SHEIKH, H. R., AND SI-MONCELLI, E. P. Image quality assessment: from error visibility to structural similarity. IEEE transactions on image processing 13, 4 (2004), 600–612. [35] WEBRTC.ORG. WebRTC Native Code. https://webrtc.org/native-code. [36] WILKINS, P., XU, Y., QUILLIO, L., BANKOSKI, J., SA-LONEN, J., AND KOLESZAR, J. VP8 Data Format and Decoding Guide. RFC 6386, Oct. 2015. [37] WINSTEIN, K., AND BALAKRISHNAN, H. Mosh: A State-of-the-Art Good Old-Fashioned Mobile Shell. In ;login:(37, 4, August 2012). [38] WINSTEIN, K., AND BALAKRISHNAN, H. Mosh: An in-teractive remote shell for mobile clients. In 2012 USENIX Annual Technical Conference (USENIX ATC 12) (2012), USENIX. Available at https://mosh.org., pp. 177–182. [39] WINSTEIN, K., SIVARAMAN, A., AND BALAKRISHNAN, H. Stochastic forecasts achieve high throughput and low delay over cellular networks. In 10th USENIX Sympo-sium on Networked Systems Design and Implementation (NSDI ’13) (2013), USENIX, pp. 459–471. [40] WU, Y., WU, C., LI, B., AND LAU, F. C. M. vSkyConf: Cloud-assisted multi-party mobile video conferencing. In ACM MCC (Aug. 2013). [41] XU, Y., YU, C., LI, J., AND LIU, Y. Video telephony for end-consumers: Measurement study of Google+, iChat, and Skype. In IMC (Nov. 2012). [42] YAN, F. Y., MA, J., HILL, G., RAGHAVAN, D., WAHBY, R. S., LEVIS, P., AND WINSTEIN, K. Pantheon: the training ground for Internet congestion-control research. Measurement at http://pantheon.stanford.edu/result/1622/. [43] YAP, K.-K., HUANG, T.-Y., YIAKOUMIS, Y., MCKE-OWN, N., AND KATTI, S. Late-binding: how to lose fewer packets during handoff. In Proceedings of the 2013 Work-shop on Cellular Networks: Operations, Challenges, and Future Design (2013), ACM, pp. 1–6. [44] YIN, X., JINDAL, A., SEKAR, V., AND SINOPOLI, B. A control-theoretic approach for dynamic adaptive video streaming over HTTP. In SIGCOMM (Aug. 2015). [45] ZHAI, F., AND KATSAGGELOS, A. Joint Source-Channel Video Transmission. Morgan & Claypool, 2007. https: //doi.org/10.2200/S00061ED1V01Y200707IVM010. [46] ZHANG, X., XU, Y., HU, H., LIU, Y., GUO, Z., AND WANG, Y. Modeling and analysis of Skype video calls: Rate control and video quality. IEEE Trans. Multimedia 15, 6 (Oct. 2013), 1446–1457.